SEO in Zeiten von KI
mit BigQuery und Experimentation
- GSC und GA4 in BigQuery vereint: volle Sicht von Query bis Conversion.
- SEO nach Geschäftswert priorisiert und per A/B-Tests optimiert.
- Fokus auf Conversions statt bloßer Sichtbarkeit – auch mit KI-Overviews.
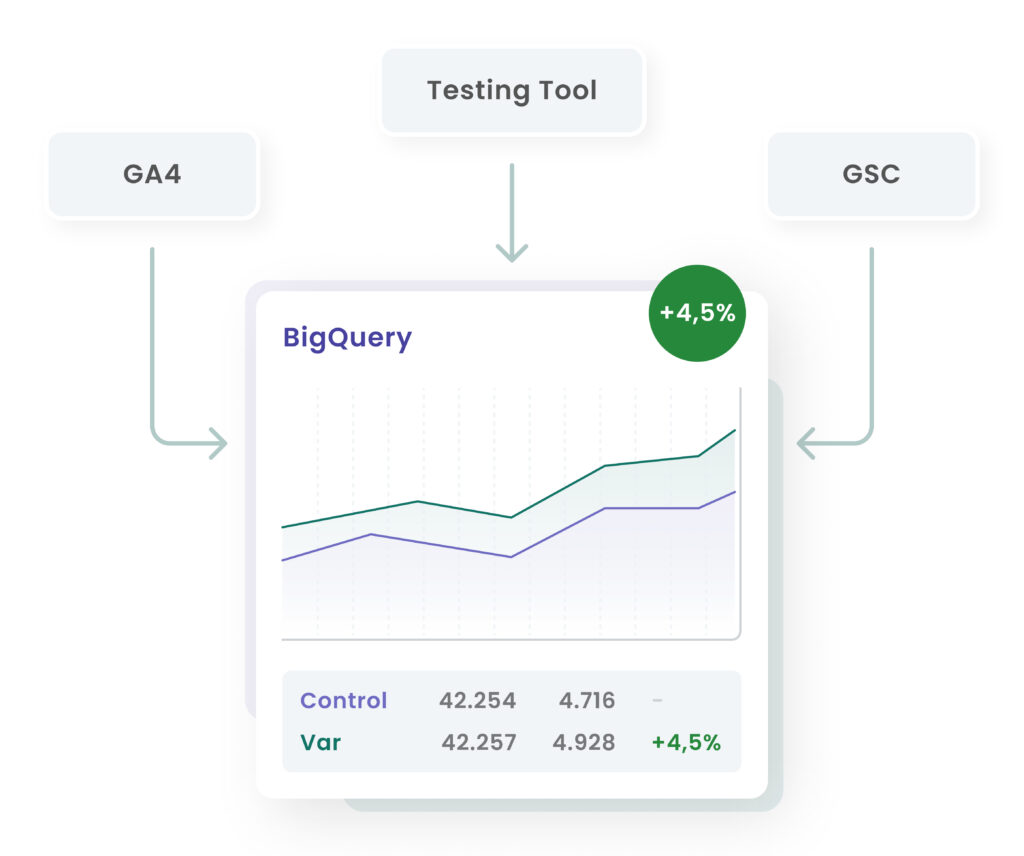
Praktische Tipps für Einsteiger
Der Einstieg in eine relativ komplexe Abfrage wie diese kann sich wie ein großer Sprung anfühlen, aber Sie müssen kein SQL-Experte sein, um davon zu profitieren. Hier sind ein paar Tipps für den Einstieg:
Definieren Sie zuerst Ihre Variablen: In den ersten Zeilen der Abfrage werden Variablen für Ihr Start- und Enddatum (start_date, end_date) sowie Ihre Experimentvarianten-Zeichenfolgen (variant_a, variant_b) definiert. Ändern Sie diese ganz oben im Skript, um sie an Ihren spezifischen Test anzupassen. Hier können Sie die Analyse ganz einfach anpassen. Dies ist eine bewährte Methode, die die Abfrage wiederverwendbar macht und das Fehlerrisiko verringert.
Fangen Sie einfach an: Versuchen Sie nicht, jede Zeile des Codes auf einmal zu verstehen. Die Abfrage besteht aus mehreren Unterabfragen (den WITH-Klauseln). Jede davon ist ein kleines, überschaubares Teil des Puzzles. Führen Sie zunächst nur den Teil gsc_data aus, um die Ausgabe zu sehen, dann den Teil variant_data und so weiter. Dieser schrittweise Ansatz hilft Ihnen, Ihr Verständnis schrittweise aufzubauen.
Konzentrieren Sie sich auf die Verknüpfungen: Der wichtigste Teil des gesamten Skripts ist die Art und Weise, wie die verschiedenen Teile miteinander verbunden sind. Beachten Sie die LEFT JOIN-Anweisungen im Abschnitt user_level_data. Dies ist entscheidend, da dadurch sichergestellt wird, dass wir alle unsere Variantenbenutzer behalten, auch diejenigen, die nicht konvertiert sind. Ein INNER JOIN würde Benutzer ohne Kauf entfernen, was zu einer verzerrten Konversionsrate führen würde. Der LEFT JOIN bewahrt die vollständige Testgruppe, was für eine genaue A/B-Testanalyse unerlässlich ist.
Lesen Sie die Kommentare: Die Kommentare (gekennzeichnet mit –) in der Abfrage sollen Ihnen helfen. Sie erklären, was jeder Abschnitt des Codes bewirkt. Lesen Sie sie sorgfältig durch, sie sind Ihr Leitfaden durch die Logik des Skripts.
Verwenden Sie die endgültige Ausgabe: Die endgültige Ausgabe des Skripts ist eine Tabelle mit zwei Hauptteilen: query_level_results und overall_results. Die erste Tabelle zeigt Ihnen, wie jede Variante bei bestimmten Suchanfragen abgeschnitten hat, und die zweite gibt Ihnen eine allgemeine Zusammenfassung. Hier finden Sie die Antworten auf Ihre Kernfragen: „Wo läuft es gut?“, „Wo läuft es schlecht?“ und „Wo gibt es ungenutztes Potenzial?“.
Dieses Skript ist mehr als nur ein Berichterstellungstool. Es ist ein grundlegendes Framework, mit dem Sie von der Analyse zu selbstbewusstem Handeln übergehen können. Es liefert Ihnen die präzisen Daten, die Sie benötigen, um Probleme zu identifizieren, Hypothesen zu formulieren und diese mit wissenschaftlicher Genauigkeit zu testen.
Aufschlüsselung der Abfrage
Ein Skript wie dieses mag auf den ersten Blick einschüchternd wirken, basiert jedoch auf einem einfachen Prinzip: Wir verbinden verschiedene Informationstabellen mithilfe einer eindeutigen Benutzer-ID. Die gesamte Abfrage wird mithilfe einer Reihe von Common Table Expressions (CTEs) erstellt, also den Teilen, die mit WITH beginnen. Stellen Sie sich jede WITH-Anweisung als einen in sich geschlossenen, logischen Schritt in unserer Datenverarbeitung vor. Es ist wie beim Bauen mit LEGO-Steinen: Sie erstellen zunächst einige einfache Blöcke und setzen diese am Ende zu einem vollständigen Modell zusammen.
Schauen wir uns die einzelnen „Bausteine” genauer an:
gsc_data: Dies ist unser Ausgangspunkt. Wir weisen BigQuery an, unsere Search Console-Tabelle aufzurufen und alle Daten für einen bestimmten Zeitraum abzurufen. Dabei werden Impressionen, Klicks und Seiten aggregiert, sodass wir eine Basis für unsere organische Performance erhalten.
variant_data: Hier rufen wir Daten direkt aus unseren GA4-Ereignissen ab. Insbesondere suchen wir nach dem benutzerdefinierten Ereignis, das protokolliert, welcher Experimentvariante (A oder B) ein Nutzer ausgesetzt war. Dadurch wird die wichtige Verbindung zwischen einem Nutzer und dem Test, an dem er teilgenommen hat, hergestellt.
organic_users: Dieser Teil der Abfrage identifiziert alle Nutzer, die über eine organische Google-Suche auf unsere Website gekommen sind. Er hilft uns, unsere Daten zu filtern, um sicherzustellen, dass wir nur die Nutzer analysieren, die für unser SEO-bezogenes Experiment relevant sind.
user_purchases & user_add_to_cart: Hier erhalten wir die Conversion-Daten (Hinweis: Das Beispiel verwendet E-Commerce-KPIs, diese können jedoch sehr gut durch Lead-Gen-Conversions ersetzt werden). Wir bitten BigQuery, alle Kauf- und add_to_cart-Ereignisse zu finden und sie mit unseren Nutzern zu verknüpfen. Wir betrachten nicht nur die Anzahl der Conversions, sondern auch andere wertvolle Kennzahlen wie den Gesamtumsatz.
Wenn wir zu den Abschnitten user_level_data und query_level_results kommen, haben wir die ganze schwere Arbeit bereits hinter uns. Das Skript führt dann alle diese kleineren Datensätze anhand der eindeutigen user_pseudo_id zusammen und aggregiert schließlich alle Daten, um eine klare, leicht lesbare Ausgabe zu liefern. Dies ist die Kernlogik, die Ihre isolierten Daten in ein einheitliches Modell umwandelt, sodass Sie Fragen wie die folgende beantworten können: „Hat der neue Seiteninhalt die mobilen Conversions für hochfrequente Long-Tail-Keywords erhöht?“

Fragen zu dem Skript?
Der Autor, Bas Linders, freut sich über einen Austausch und steht für Fragen oder Verbesserungsvorschläge zur Verfügung.
Das bereitgestellte SQL-Skript dient als hilfreiches Tool, um die Verbindung zwischen GSC, GA4 und BigQuery zu optimieren. Im Artikel haben wir Tipps und Beispiele zur Nutzung gegeben, doch die Verantwortung für die Anwendung und etwaige Auswirkungen, wie das Überschreiten von BigQuery-Limits, liegt beim Nutzer.